[2024]
[2023]
[2022]
[2021]
[2020]
[2019]
[2018]
[2017]
[2016]
[2015]
[2014]
[2013]
[2012]
[2011]
[2010]
[2009]
December
November
October
September
August
July
June
May
April
March
February
January
[2008]
[2007]
[2006]
[2005]
[2004]
[2003]
[Thu Apr 30 14:34:44 CEST 2009]
Let's do a roundup of a few links I have been gathering for a while now. First of all, we have the Operating System Documentation Project, apparently put together by someone in Germany. It contains some basic information about lots of operating systems (both alive and dead), as well as plenty of screenshots, of course.
Second, I also came across a short piece published on ArsTechnica about the advanced features added to the GNU Screen command in the most recent release of Ubuntu. The improvements are bundled in a new package called screen-profiles and include tools that make GNU Screen easier to use and configure.
Third, The Linux and Unix Menagerie publishes an article
explaining the differences between /dev/zero and /dev/null. So, what are
the main differences and similarities? When you write to them, both behave
the same way: your output goes to la-la-land. Reading, on the other hand, is
quite different: while /dev/null is a black hole that produces nothing
whatsoever, just a vast vacuum; /dev/zero, however, behaves in a different
way and returns zeroes until you stop reading from it. So, who cares? What
good is it to have things like /dev/zero and /dev/null lying out there in the
filesystem? Well, you can use /dev/null to create a zero byte file. You can
also use /dev/zero to zero out a file that you can use later to create a
filesystem using the
Finally, Fast Company published this nifty piece about nine ideas to save the world inspiread by Buckminster Fuller. There is a little bit of everything: a system of cyclone proof shelters, a portable toilet that transforms waste into fertilizer specifically designed for the developing world, a system to create fresh water from seawater designed with the ambition to replant the Sahara desert, the simple tools created by Kickstart to make it easier for people in the underdeveloped world to start their own businesses, etc. It's a good read. {link to this story}
[Mon Apr 27 15:57:23 CEST 2009]
I had no idea that Stephen Wolfram, creator of Mathematica, was working on a new generation search engine called Wolfram|Alpha. Actually, ReadWriteWeb reports about a demo they attended. More than a traditional search engine, Wolfram|Alpha is built around a repository of curated data from public and licenses sources, all of it organized via some sophisticated algorithms. So, what's different about it? According to the article:
The author of the article explains that he doesn't see Alpha being a major competitor to Google but rather to Wikipedia. One way or another, it does show that perhaps some day Google will be in trouble, strong as they seem to be today. {link to this story}Where Alpha exceeds, is in the presentation of its "search" results. When asked for how many internet users there are in Europe, for example, Alpha returned not just the total number, but also various plots and data for every country (apparently Vatican City only has 93 Internet users).
Another query with a very sophisticated result was "uncle's uncle's brother's son". Now if you type that into Google, the result will be a useless list of sites that don't even answer this specific question, but Alpha actually returns an interactive genealogic tree with additional information, including data about the "blood relationship fraction", for example (3.125% in this case).
(...)
Alpha also has a sophisticated knowledge of physics and chemistry data, and during today's demo, we also saw examples for nutritional information, weather, and census data. Most of the data in the system is curated, but real-time financial data or weather information will go through a system that checks the data for validity, so that outliers can be identified as potentially faulty information.
[Mon Apr 27 15:37:44 CEST 2009]
Linux Magazine publishes the second part of their interview with Linus Torvalds, where the founder of Linux makes some thought-provoking comments about source code management:
{link to this story}(...) the reason a distributed SCM [source control manager] is important is not the distribution itselsf as much as the flow of information it allows. By avoiding the whole single point of concentration, you end up with the possibility for a much more dynamic development model.
And I say "the possibility", because you can certainly continue with all the old rules, and the old development model, and use a distributed SCM the same way you use any random central one, but you won't see the huge advantages if you do.
So the big piece of advice for anybody looking at switching SCMs (or if you just want to really think about the SCM you use now, and what implicit assumptions you have in your current workflow) is to think about the SCM as just a tool, but also realize that it's a tool that quite heavily constrains —or liberates— just how you work.
And a lot of the "how you work" things are not necessarily seen as limitations of the SCM itself. They end up being these subtle mental rules for what works and what doesn't when doing development, and quite often those rules are not consciously tied together with the SCM. They are seen as somehow independent from the SCM tool, and sometimes they will be, but quite often they are actually all about finding a process that works well with the tools you have available.
One such common area of rules are all the rules about "commit access" that a lot of projects tend to get. It's become almost universally believed that a project either has to have a "benevolent dictator" (often, but not always, the original author as in Linux), or the alternative ends up being some kind of inner committer cabal with voting.
And then there spring up all these "governance" issues, and workflows for how voting takes place, how new committers are accpted, how patches get committed, et cetera, et cetera. And a lot of people seem to think that these issues are very fundamental and central, and really important.
And I believe that the kinds of structures we build up depend very directly on the tools we use. With a centralized source control management system (or even some de-centralized ones that started out with "governance" and commit access as a primary issue!) the whole notion of who has the right "token" to commit becomes a huge political issue, and a big deal for the project.
Then on the other hand, you have de-centralized tools like git, and they have very different workflow issues. I'm not saying that problems go away, but they aren't the same problems. Governance is a much looser issue, since everybody can maintain their own trees and merging between them is pretty easy.
[Mon Apr 27 14:30:39 CEST 2009]
Somebody posted an interesting story a few days ago on Slashdot wondering whether or not running shoes are truly needed for sports activities. The actual story was published by the British Daily Mail and it can be read here. In reality, it's little else than an extract from a book recently published by Christopher McDougall. The whole story starts with a couple of Nike representatives visiting Stanford University to gather feedback from the company's sponsored runners about which shoes they preferred. To their surprise, the coach said that he thought that when his runners trained barefoot they ran faster and had less injuries. As the author states:
So, in conclusion, that the modern athletic shoe may be nothing but a scam. One more of those industry-manufactured needs to keep things going and make sure the economy survives. The fact is that there is no evidence at all to substantiate the idea that running shoes help prevent injuries. Yet, Nike's annual turnover exceeds US $17 billion now. Interesting indeed. {link to this story}Every year, anywhere from 65 to 80 per cent of all runners suffer an injury. No matter who you are, no matter how much you run, your odds of getting hurt are the same. It doesn't matter if you're male or female, fast or slow, pudgy or taut as a racehorse, your feet are still in the danger zone.
But why? How come Roger Bannister could charge out of his Oxford lab every day, pound around a hard cinder track in thin leather slippers, not only getting faster but never geting hurt, and set a record before lunch?
Then there's the secretive Tarahumara tribe, the best long-distance runners in the world. These are a people who live in basic conditions in Mexico, often in caves without running water, and run with only strips of old tyre or leather throngs strapped to the bottom of their feet. They are virtually barefoot.
Come race day, the tarahumara don't train. They don't stretch or warm up. They just stroll to the starting line, laughing and bantering, and then go for it, ultra-running for two full days, sometimes covering over 300 miles, non-stop. For the fun of it. One of them recently came frist in a prestigious 100-mile race wearing nothing but a toga and sandals. He was 57 years old.
(...)
Dr. Daniel Lieberman, professor of biological anthropology at Harvard University, has been studying the growing injury crisis in the developed world for some time and has come to a startling conclusion: "A lot of foot and knee injuries currently plaguing us are caused by people running with shoes that actually make our feet weak, cause us to over-pronate (ankle rotation) and give us knee problems.
"Until 1972, when the modern athletic shoe was invented, people ran in very thin-soled shows, had strong feet and had a much lower incidence of knee injuries".
[Sat Apr 25 17:36:30 CEST 2009]
Elizabeth Montalbano, from IDG, shares with us an interesting take on the Oracle-Sun merger:
So, what features are the most likely to make the move from OpenSolaris to Linux, according to these analysts? For the time being, most of the talk is about DTrace and their Containers technology, which allows for the OS to be divided into discrete parts that can be managed separately. Honest, I'm not sure either move makes much sense. Linux already has virtualization, and it works pretty well. As for DTrace, the tool is nice, but difficult to port to a different operating system. It may make more sense to write it from scratch, and there are already projects to do that. {link to this story}Oracle may end up merging the best of OpenSolaris with Linux once it takes control of Sun Microsystems, but it is unlikely to kill off Sun's widely used Solaris OS, analysts said.
On a conference call Monday, Oracle Chairman Larry Ellison said one of the primary reasons Oracle is interested in Sun is for its Unix-based Solaris OS, which has long been an important platform for Oracle's database and has a fairly healhty and significant installed base.
Oracle is also a big proponent of Linux, however, so the deal raises questions about how Oracle might reconcile the two OSes. Indeed, just two weeks ago Oracle's corporate chief architect and top Linux engineer, Edward Screven, said Oracle would like to see Linux become the default operating system for the data center, so that customers don't even think about choosing another OS.
"What we are working to do in the data center... is to make Linux the default for the data center OS," Screven said in a speech at the Linux Foundation Collaboration Summit in San Francisco. "We want there to be no question."
[Sat Apr 25 14:06:09 CEST 2009]
Linux Magazine publishes an interview with Linus Torvalds where the founder of Linux makes a few comments well worth referring to here. First of all, with regards to the relationship between kernel hackers and their employeers, Linus says the following:
That's absolutely right. Most kernel hackers (Linus Torvalds, Alan Cox, Theodore Tso, Greg Kroah-Harman, Andrew Morton...) are well known by themselves. They have reached a star status within the computing world without any doubt, and this allows them a freedom that they wouldn't have otherwise. They can move from company to company without much problem and therefore, if needed, resign from a given job if they stop feeling comfortable or the company asks them to do something they strongly disagree with. This is definitely good for the open source projects they work for, but it's also good for the end users. It is a direct consequence of the open source development model that perhaps we have never thought about much.And by the way, talking about changing employers: one thing I think is very healthy is how kernel developers are kernel developers first, and work for some specific company second. Most of the people work for some commercial entity that obviously tends to have its own goals, but I think we've been very good at trusting the people as people, not just some "technical representative of the company" and making it clear to companies too.
The reason I bring that up is that I think that ends up being one of the strengths of open source —with neither the project nor the people being too tied to a particular company effort at any one time.
I'd also like to stress Linus' words about the scalability of the kernel code and how to maintain the codebase in order to achieve this. After the interviewer states that "before Linux" nobody would have believed that the same kernel would be running on supercomputers and cell phones, Linus replies with this:
First of all, it's nice to see a worldwide renowned software engineer like Linus Torvalds acknowledge errors or, at the very least, being flexible enough to correct course in the middle of a trip. Most people are jut too strongheaded to do that. Second, in order to realize how important of an accomplishment this is in software development terms, consider the amount of different versions of the Windows kernel out there to adapt to different device and even functionality. In the case of Linux, it all stems from a single codebase. {link to this story}Personally, I woudln't even say "before Linux". For the longest time "after Linux" I told people inside SGI that they should accept the fact that they'd always have to maintain some extra patches that wouldn't be acceptable to the rest of the Linux crowd just because nobody else cared about scaling quite that high up.
So I basically promised them that I'd merge as much infrastructure patches as possible so that their final external maintenance patch-set would be as painfree to maintain as possible. But I didn't really expect that we'd support four-thousand-CPU configurations in the base kernel, simply because I thought it would be too invasive and cause too many problems for the common case.
And the thing is, at the time I thought that, I was probably right. But as time went on, we merged more and more of the support, and cleaned up things so that the code that supports thousands of CPUs would look fine and also compile down to something simple and efficient even if you only had a few cores.
So now, of course, I'm really happy that we don't need external patches to cover the whole spectrum from small embedded machines to big thousand-node supercomputers, and I'm very proud of how well the kernel handles it. Some of the last pieces were literally merged fairly recently, because they needed a lot of cleanup and some abstraction changes in order to work well across the board.
And now that I've seen how well it can be done, I'd also hate to do it any other way. So yes, I believe we can continue to maintain a single source base for wildly different targets, ranging from cell phones to supercomputers.
[Tue Apr 21 13:09:32 CEST 2009]
Just to prove how fast-paced the business world is, the deal between IBM and Sun Microsystems fell through a couple of weeks ago, but yesterday we were all surprised to hear that Oracle will now buy Sun for US $7.4 billion. Two of the Sun's technologies proved to be attractive to Larry Ellison, apparently: Java and Solaris. No surprises when it comes to Java, but things are a bit different with respect to Solaris, which many people see as a dying operating system. Not so Ellison, apparently:
So, is that it? Is that the only reason that might have attracted Ellison to Sun? No way. As a matter of fact, there is a good chance that he may have made his decision more out of fear of what could have been in case IBM had managed to purchase them than anything else."The Solaris operating system is by far the best Unix technology available in the market," Ellison said. "That explains why more Oracle databases run on the Sun Sparc-Solaris platform than any other computer system."
Or, to put it another way, chances are that IBM would have let Solaris die a very slow death and, with it, Oracle would have been severely affected too. Just in case we had any doubt about Ellison's true intentions, let's see what Computer World reports as his plans for the SPARC architecture:If IBM had bought Sun, it would have created an opening to expand use of its DB2 database running on AIX at Oracle's expense.
It may, but as a dying technology. Oracle is in the business of selling database software, not hardware. If a given operating system gives its own database an edge, they may place a bet on it but that's about it. For the same reasons, it wouldn't surprise me to see Ellison make a similar move in the Linux market. If Linux is expanding on the server market, he has an interest to make sure that it is nicely integrated with his own database to continue satisfying his customers....Ellison didn't make any long-term commitment to the Sparc hardware: He called Solaris "the hear of the business" for Sun. And while Oracle sees the acquisition as giving it the ability to sell ready-made systems out of the box —"complete and integrated computing systems from database to disk," as Ellison put it— that doesn't mean those systems have to be sold on Oracle-branded hardware.
Nonetheless, analysts said that even if Oracle doesn't see much of future in Sun's hardware, the road map for Sparc systems may well extend a decade or more.
But these are not the only technologies owned by Sun. What about the others?
Computer World reports that, according to the analysts, MySQL could thrive under Oracle ownership. To be fair, Sun didn't seem to be doing a good job at it. Plenty of MySQL developers have been leaving Sun in the past few months due to strong disagreements about the direction things were taking. For the most part, analysts point out that there is plenty of room for multiple databases within enterprise data centers. I have my doubts. Nevertheless, the fact that MySQL is an open source product makes it possible, at the very least, to continue developing it regardless of what Oracle management decides. That's a guarantee one wouldn't have with closed-source commercial products. Actually, it's a guarantee one doesn't have with Solaris or even Oracle, assuming they are ever bought by a competitor in the near future. Who said open source didn't make a big difference? {link to this story}For one, Ellison barely mentioned the MySQL open-source database, a rival to Oracle's flagship software that Sun acquired last year. No questions were taken during the conference call, making it impossible to press Ellison on that issue.
[Tue Apr 21 13:05:56 CEST 2009]
Some people do have too much time in their hands! The experiment is quite interesting nonetheless. Queen's Bohemian Rhapsody played with electronic appliances!
{link to this story}
[Sun Apr 19 13:15:23 CEST 2009]
Mark Shuttleworth writes in his blog about the concept of meta-cycles in software releases:
Good use of blogging indeed. He writes about an issue without having fully made his mind and leaves it to people to comment on it before he writes a new piece. That's precisely how the traditional essay style was born.Six-month cycles are great. Now let's talk about meta-cycles: broader release cycles for major work. I'm very interested in a cross-community conversation about this, so will sketch out some ideas and then encourage people from as many different free software communities as possible to comment here. I'll summarise those comments in a follow-up post, which will no doubt be a lot wiser and more insightful than this one.
So, what does Shuttleworth propose?
Remember when Ubuntu and GNOME started the trend a few years ago? There was a big controversy. Quite a few people considered the practice of regular releases quite contrary to the spirit of free software, a practice that made more sense in the traditional world of commercial software engineering, but not in the open source world. Well, as Shuttleworth states, the ones who pushed for this new trend seemed to be right in the end. Regular cycles have brought us more consistency and predictability, as well as a more polished product. I don't think the nice inroads that Shuttleworth's own Ubuntu distribution has made in the desktop market the last few years would have ever been possible without it. Yet, there are issues with this new approach too:The practice of regular releases, and now time-based releases, is becoming widespread within the free software community. From the kernel, to GNOME and KDE, to X, and distributions like Ubuntu, Fedora, the idea of a regular, predictable cycle is now better understood and widely embraced. Many smarter folks than me have articulared the benefits of such a cadence: energising the whole community, REALLY releasing early and often, shaking out good and bad code, rapid course correction.
Even more important than all this, there is something to say for the big leap forwards too. The shorter release cycle adopted lately does help stabilize things by focusing on improving the current framework and iron out the wrinkles. However, it lacks ambition. It makes the grand visions a bit more difficult. So, perhaps we should strive to a combination of both approaches. Or, as Shuttleworth puts it:...there are also weaknesses to the six-month cycle:
.
- It's hard to communicate to your users that you have made some definitive, signficant change,
- It's hard to know what to support for how long, you obviously can't support every release indefinitely
Finally, Shuttleworth shares a few questions and options to kick off the debate: what would the "best practices" of a meta-cycle be? What's a good name for such a meta-cycle? Is it true that the "first release of the major cycle" (KDE 4.0, Python 3.0) is best done as a short cycle that does not get long term attention? Which release in the major cycle is best for long term support? Is a whole-year cycle beneficial? How do the meta-cycles of different projects come together? {link to this story}
- Rapid, predictable releases are super for keeping energy high and code evolving cleanly and efficiently, they keep people out of a deatchmarch scenario, they tighten things up and they allow for a shakeout of good and bad ideas in a coordinated, managed fashion.
- Big releases are energising too. They are motivational, they make people feel like it's possible to change anything, they release a lot of creative energy and generate a lot of healthy discussion. But they can be a bit messy, things can break on the way, and that's a healthy thing.
[Sun Apr 19 12:41:54 CEST 2009]
Interesting piece on how IBM makes math cool and relevant in its research:
{link to this story}IBM knows how to make math not only fun and cool, but also current by applying math to issues such as social media, among other things. Big Blue is using math to analyze things like Twitter feeds and blogs, as well as to create algorithms for business analytics and optimization.
[Sat Apr 18 14:45:33 CEST 2009]
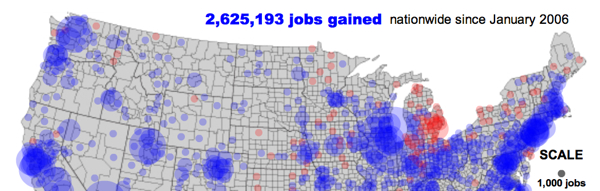
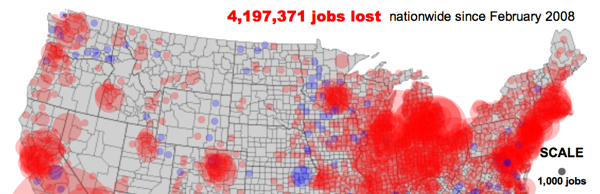
The O'Reilly Radar carries a story about an interactive map on Slate's Moneybox section showing the rate of jobs creation and destruction throughout the US. The maps are impressive. It's a great work of data visualization. Here are a couple of snippets:
The actual Slate piece can be found here. Think of the enormous potential of this type of maps. {link to this story}
[Fri Apr 17 13:09:08 CEST 2009]
systhread.net has published a short history of the X Window Managers in two parts that's well worth a look (here is the liknk to the second part). The introductory paragraph is a good synthesis:
Starting from that point, the author proceeds with a quick introduction of the most important window managers "roughly in order of appearance": xwm, twm, the Motif Window Manager, fvwm, AfterStep, WindowMaker, Enlightenment, XFCE, Blackbox, Fluxbox, etc. While some users may find this quite confusing, I do like the fact that in the UNIX and Linux world one can choose his/her own window manager. Some see it as a weakness, but I prefer to think of it as a strength and, above all, a way to avoid the dangers of overdependence on a single solution. As a matter of fact, every now and then I force myself to use a different window manager or desktop environment for a couple of weeks in order to keep some sanity and make sure I don't get too set on my ways. {link to this story}The X11 suite of graphical display capabilities sets policy but does not define application; this is to say it provides a vehicle to transport graphics using a protocol. There are advantages and disadvantages to such a method beyond the scope of this material excepting one particular advantage: the implementation of the X suite allows for the creation of a wide variety of graphical window managers.
[Fri Apr 17 11:22:43 CEST 2009]
A friend just sent me this spectacular video in an email:
At first, I thought it might be an ellaborate hoax, but then realized that even Wikipedia has an entry for wingsuit flying. So, after so many centuries, it turned out that the human being has been able to fly without resorting to any sort of convoluted machinery after all. There goes a paean to human ingenuity... but I don't think I will be giving this a try anytime soon. {link to this story}
wingsuit base jumping from Ali on Vimeo.
[Thu Apr 16 16:01:20 CEST 2009]
We are so used to hearing about the evil dangers of tools like Facebook and Twitter, the horrible, negative impact it has on the younger generations and how it is driving them towards iliteracy and stupidity that something like this comes as a surprise. Yet, what Mr. Camplese is doing is applying a tactic that has been applied time and over again: do not fight new inventions, for it is a waste of time. Instead, join them, use them and integrate them. In other words, while other people are struggling to fight against trends that are unstoppable, Mr. Camplese is experimenting with them and adapting them to his own needs using his imagination. His students are twittering while he is lecturing, sure, but at least they are twittering about what's been discussed in class. Besides, as the piece explains, they are also reaping some benefits:Cole W. Camplese, director of education-technology services at Pennsylvania State University at University Park, prefers to teach in classrooms with two screens —one to project his slides, and another to project a Twitter stream of notes from students. He knows he is inviting distraction —after all, he's essentially asking students to pass notes during class. But he argues that the additional layer of communication will make for richer class discussions.
The end result of all this? Among other things, we tear down the traditional walls of the classroom:Once students warmed to the idea that their professors actually wanted them to chat during class, students begin floating ideas or posting links to related materials, the professor says. In some cases, a shy student would type an observation of question on Twitter, and others in the class would respond with notes encouraging the student to raise the topic out loud. Other times, one of the professors would see a lionk posted by a student and stop class to discuss it.
That's a professor who is not afraid of experimenting and trying new things! Good for him! {link to this story}Still, when Mr. Camplese told me about his experiment soon after he spole at The Chronicle's Tech Forum, I couldn't help thinking that it sounded like a recipe for chaos, and I told him so. He replied that his hope is that the second layer of conversation will disrupt the old classroom model and allow new kinds of teaching in which students play a greater role and information is pulled in from outside the classroom walls. "I'm not a full-time faculty member," he said, "I use my classrooms as an applied-research lab to decide what to promote as new solutions for our campus."
[Tue Apr 14 10:18:01 CEST 2009]
Now, tell me if this doesn't sound like science fiction. Apparently, California is seriously considering using a set of orbiting solar panels as a source of energy:
Think of it. If the solar panels are in orbit, there is no day and night. Obviously, this means that these panels, unlike the ones we have down here, will be able to churn out energy 24x7. Some interesting idea, huh? But wait, what if this beam could become some sort of laser of death?California's next source of renewable power could be an orbiting set of solar panels, high above the equator, that would beam electricity back to Earth via a receiving station in Fresno county.
Pacific Gas and Electric Co. has agreed to buy power from a startup company that wants to tap the strong, unfiltered sunlight found in space to solve the growing demand for clean energy.
Sometime before 2016, Solaren Corp. plans to launch the world's first orbiting solar farm. Unfurled in space, the panels would bask in near-constant sunshine and provide a steady flow of electricity day and night. Receivers on the ground would take the energy —transmitted through a beam of electromagnetic waves— and feed it into California's power grid.
[Cal Boerman, Solaren's director of energy services] also dismissed fears, raised in the past, that the transmission beam could hurt bird or airline passengers who stray into its path. The beam would be too diffuse for that.
"This isn't a laser death ray," Boerman said. "With an airplane flying at altitude, the sun is putting about four or five times more energy on the airplane than we would be."
Placing solar panels in orbit would solve two of the biggest problems facing the solar industry.
Terrestrial large-scale solar farms only generate electricity during the day, and their output varies with the seasons. They also require large tracts of land, often hundreds of acres for a single installation.
Those problems vanish in space. The Solaren project would experience constant sunlight except for brief interruptions during the spring and fall equinox periods. Obviously, land wouldn't be an issue. And the sunlight hitting Solaren's facility would be eight to 10 times more powerful than the light reaching Earth through the planet's atmosphere.
Of course, plenty of technical details still need to be worked out... not to speak of the cost. However, to me, it seems like good old American ingenuity at its best. It may not work in the end. It may be a pure pie in the sky project. However, if it can be made to work, they will do it. Yes, hundreds of thousands of crazy projects fail every year, but a few do make it. Without trying as many of them as possible, we'd never benefit from things like television, the Internet or Google. Americans are taught since a very young age that trying different things is good, one shouldn't be afraid of failure and dreaming is what makes us human. We need a bit more of that in our own schools over here in Europe. {link to this story}
[Sun Apr 12 17:51:44 CEST 2009]
While checking the technology news a few days ago I came across a post on Slashdot about why the CAPTCHA approach is doomed that I thought was interesting. CAPTCHA is a mechanism that has been used for a while now on the web to make sure that there is truly a human being behind the computer submiting a form, instead of an automated script sending out garbage. Well, the Slashdot post links to an entry on the Technobabble Pro blog that discusses the gotchas with CAPTCHA. According to the author, it has three inherent gotchas:
Of the three arguments, the third and last one sounds the most interesting, I think. Perhaps the fact that it's not a technical argument is what makes it more appealing to me. When thinking about these issues, people who work with technology tend to forget that technology functions in a social context. The weakness of most security systems tends to be precisely in its social side, not in the technology itself. {link to this story}The mental effort gotcha. Sure, we humans are much smarter than computers, but actually demonstrating that (where it counts) takes time and effort. Even a human interrogator can have a hard time telling humans and computers apart. Website users aren't willing to spend more than a few seconds solving a CAPTCHA, and they already frequently complain that CAPTCHA are too hard. This means CAPTCHAs need to be simple puzzles we can solve relfexively and mechanically, without warming up the deeper thought processes. This just about implies the solution is likely to be something we could emulate on a computer with reasonable effort.
The accessibility gotcha. CAPTCHAs are inherently terrible for people with disabilities (and are frequently reviled for this). The blind can't see image-based CAPTCHAs, and visually-impaired users don't have it much easier, because of the deliberately unclear images. The audio alternatives are frequently too hard for humans or too easy for bots, and of course they're inaccessible to deaf or hearing-impaired users. CAPTCHAs which use text can get too difficult for some dyslexics, and so on. Anda even if the mental effort fotcha didn't stop you trying to base a CAPTCHA on more "intelligent" puzzles, would you really want to build an inaccessibility to children or the mentally challenged? Trying to keep a site reasonably accessible means using multiple alternative CAPTCHAs, and (again!) keeping those puzzles quite simple.
The economic gotcha. This is the CAPTCHA gotcha most likely to eliminate CAPTCHAs as an effective tool. Suppose a genuinely hard-to-break CAPTCHA scheme does emerge, and is used to filter access to a valuable resource, for example webmail or social network accounts. Suppose you're a spam-baron and need to open one hundred thousand such accounts. You could pay a small team (in a third-world country with cheap labour, of course) just to solve CAPTCHAs manually for you. The experts say you need 10 seconds per puzzle, or 278 hours total. That's a little more than one work month, which could set you back a few hundred dollars, if you insist on highly-qualified personnel (and even paying taxes!). If you made a business of it, you could probably knock that down to a hundred dollars. I'm not an expert on the malware economy, but I beleive that's a fair price to pay, given other typical rates for resources. You'd certainly hope the many millions of spam messages you can now send will more than recover that investment. It's also a great outsourcing niche: just specialise in solving CAPTCHAs, and sell the service. And it's even been suggested that hackers may already be solving some CAPTCHAs with an alternative workforce: they require users of their own porn or pirated content websites to solve the CAPTCHAs from sites they wish to access. Effectively, they're paying them in pictures or MP3s (which may be even chaper for them).
[Sat Apr 11 17:53:35 CEST 2009]
Linux Magazine has published an article titled The Clustering Way about Intel's Nehalem platform that is worth the read. After praising Intel's improved handling of memory bandwidth, power saving and virtualization features, the author goes on to discuss his experience while performing some benchmarks on the new micro-architecture:
So, how about the companies that bet it all on NUMA?...Now that is interesting. A code runs better over IB than over shared memory. Conventional wisdom would dictate that running anything over shared memory vs distributed memory should provide a better result. In my tests I found the opposite to be true in some cases —by over a factor of two! This was a prime example of how a memory bottleneck can effect performance. Note that not all codes improved indicating the application dependent nature of memory bandwidth.
(...)
The preceding was a long argument to reach the point I wish to make —The AMD and now Intel multi-core processors are a cluster architecture. AMD pioneered the idea and should be given credit for doing it right in the first place with the introduction of HyperTransport. Intel has just confirmed the approach with the QuickPath interconnect. If you think about it, modern multi-core processor have a core processor, memory controller, and memory connected to other similar cores over a high speed interconnect. Sounds like a cluster to me. The multi-core processors take it stepo further however, and have done what some cluster tecnologists have wanted for years —shared memory. In both of the designs all cores can see all the memory on the motherboard. They cannot however, access all memory at the same speed. Local memory access is faster than through the interconnect. This type of architecture is called Non-Uniform Memory Access (NUMA).
To the programmer, it all looks the same. To end user, variation or even poor run times can result from a NUMA architecture if the data placement is non-optimal. In such a tightly coupled situation there is another issue as well —CPU cache. Recall that cache is used to compensate for the speed mismatch between CPU and memory. Keeping often used memory items in high speed cache memory helps to mitigate this problem, but there are cases where cache does not work either due to poor program design or algorithm requirements. To address cache on multi-core architectures, designers have introduced cache coherency (cc) into the architectures. This architecture is called of course ccNUMA. The trick is to keep all the caches in sync with each other. For iosntance, if core A is working with a certain memory location that is in cache, the actual memory is considered "dirty" (not valid) and cannot be used by any other cores. If core B needs to read that same memory location, then the caches must be coherent so that the correct value is used. Cache coherency is tricky and takes special hardware.
Like NUMA, ccNUMA is transparent to the programmer. To the end user, however, variation in run time can be the norm as cache coherency depends on what is in the cache and what else is running on the cores. The OS will often try to keep a process on the same core to help reduce cache data movement, but the OS also tries to keep the cores balanced and thus some process movement may be necessary. With Linux there are methods to "pin" a process to a core which overried the ability of the OS to move a process at will.
As usual, the low-end catches up with the high-end and eats up its market. Sure, it's still possible for a high-end company to survive, but it has to be quite flexible and quick to adapt to the changing situations. That's how the technology market has been working for the past two decades or so. It shouldn't surprise anyone. {link to this story}There were companies who sold ccNUMA machines before advent of multi-core. Companies like SGI and Convex developed scalable high performance machines with ccNUMA capability. They were met wirh some market success. What pushed them to a small corner of the market? That would be MPI on commodity hardware. That is right, the cluster. Many problems worked just as well in a distributed memory environment than in a ccNUMA environment. Some may argue that programming in a ccNUMA is "easier" than MPI programming, however, that did not seem to stop people from using clusters. Indeed, the low cost of commodity hardware over the high end ccNUMA designs made it worth considering the MPI approach.
[Fri Apr 10 13:27:56 CEST 2009]
Linux Magazine publishes an interview with Theodore Tso about the transition from ext3 to ext4 that makes for an interesting read. Among other things, Tso explains why the project to write a new file system was even started:
Now, that last comment is a very good illustration of the benefits of open source. Precisely because the code is open, companies like Google can contribute features that they need, which also means that everybody else will benefit from it and, on top of that, the code will be tested and debugged by none other than Google itself. Who can beat that? {link to this story}There were a number of features that we've wanted to add to ext3 —to improve performance, support larger number of blocks, etc.— that we couldn't without breaking backwards compatibility, and which would take a long enough time to stabilize that we couldn't make those changes to the existing ext3 code base. Some of those features included: extents, delayed allocation, the multiblock allocator, persistent preallocation, metadata checksums, and online defragmentation.
Along the way we added some other new feature that were easy to add, and didn't require much extra work, such as NFSv4 compatible inode version numbers, nanosecond timestamps, and support running without a journal —which was a feature that was important to Google, and which was contributed by a Google engineer. This wasn't something we were planning on adding, but the patch was relatively straightforward, and it meant Google would be using ext4 and providing more testing for ext4, so it was a no-breainer to add that feature to ext4.
[Fri Apr 10 13:19:54 CEST 2009]
Michael Hickens writes on Google Watch about how Google's investment on YouTube seems to be panning out after all. Back when Google bought YouTube in 2006, lots of people wondered whether it made any business sense. Yes, YouTube was one of the most popular websites on earth but... how could anyone make money out of it? Well, according to Hickens, YouTube is now selling ads against 9 percent of its content, versus 6 percent a year ago. So, the answer seems clear: ads. What's interesting is how, in spite of the recession, Google still manages to make a profit even though its business is almost solely based on revenue from the ads. There is a business lesson to be learned there. {link to this story}
[Thu Apr 9 21:28:34 CEST 2009]
Steven Vaughan-Nichols has written an insightful article in Computer World about the future of five of Sun's top technologies after being bought by IBM. Most of what he says sounds straightforward enough: IBM shouldn't care much about Solaris, given its investments in AIX and Linux, as well as the dwindling importance of the UNIX market; SPARC is history; its Java products have traditionally been better than Sun's and the company more committed to open source too, so there is little to fear in that front; Netbeans is as good as dead, although chances are it will continue living as a community project; and, finally, MySQL, the de facto DBMS of Web 2.0 projects, may even benefit from the whole story after Sun's management drove most of its top programmers out of the company. In other words, that perhaps anyone who cares about Sun's products should feel happy about the fact that IBM bought them. {link to this story}
[Thu Apr 9 21:12:20 CEST 2009]
I thought that's why GPL v3 was written. Still, Allison's description is quite simple and easy to understand. {link to this story}...the fatal flaw in the GPL is that the reciprocal clause is only triggered by the act of redistribution. This works well in the world of traditional software, where in order to use a program it must be directly distributed to the recipient. Under the GPL that person then inherits the same rights to the software source code as the distributor had. But now consider the strange new world of cloud computing, and software as a service. The way software works in this world is completely different. Most of the complex logic and the actual programs themselves live as software only running within server farms, communicating solely by network requests sent from a client Web browser via downloaded javascript programs.
There is no "distribution" here, so the reciprocal clause of the GPL is never triggered. In such a world, service providers can use GPL licensed code in proprietary back-end server farms with impunity. This seems contrary to the spirit of the authors of much of the GPL licensed code used in this way, although it strictly complies with the license. It means that (...) GPL code can be used in the cloud computing market in exactly the same way as BSD code can be used in the traditional software market.
[Mon Apr 6 22:30:30 CEST 2009]
A few days ago I came across a blog post explaining the philosophy behind a new online community called minimonos that made me nod in agreement like an automaton:
OK. Sure, the author has gone a bit over the top writing about the "pressures" on the kids as a consequence of the economic crisis and the "impending environmental crisis". I don't know. Perhaps you, as a parent, should be the first one who shouldn't be worrying your kids about those issues just yet? In any case, she has a point that there are several virtual worlds or clubs out there spreading like the bad weed among kids whose sole purpose is, obviously, to sell them stuff. So much has been written about how to protect our kids from virtual sex and other abuses that, until now, we've given little thought to this other danger: our kids can also be prey to the unlimited greed of corporations. I ignore how minimonos works, but I agree that something needs to be done about it. It just doesn't worry me so much right now because my kids seemed to outgrow the online club craze. {link to this story}I started this company because, like parents everywhere, I want a better life for my children and grandchildren (not that I'm ready for grandkids!). I want a world where they are free to enjoy childhood without the pressure of worrying whether previous generations have messed it up or not.
I wonder about the pressures that our kids must feel now with the current economic crisis, coupled with the impending environmental crisis. I want kids to have a safe place to play, hang out and BE themselves, without the pressure to buy stuff.
You may not realize this, but most virtual worlds exist to solve a problem for advertisers. The advertisers' question is, "How do I sell more stuff to kids?" Why else did Disney buy Club Penguin? Why do Buildabear and Webkinz and Barbie and every other major toy manufacturer have virtual worlds? It's because the worlds give them a way of merchandising. They aren't really thinking about the kids.
I've got a different question: How can we build a virtual world where the real customers are the parent and the kid? How would it differ from the others out there?
[Wed Apr 1 14:28:37 CEST 2009]
To celebrate April
Fools' Day, YouTube announced today a "new viewing experience". After you check
their page, the string